Abstract
Key Innovation: This study presents a bio-inspired reinforcement learning framework for robotic gaze control that incorporates a habituation mechanism to regulate the exploration-exploitation trade-off, mirroring how biological attention systems filter redundant stimuli whilst remaining responsive to novel events.
Adaptive attention allocation in dynamic social environments remains a fundamental challenge for autonomous robots, requiring the integration of perceptual saliency, social context, and real-time decision-making. We present a bio-inspired reinforcement learning framework for robotic gaze control that incorporates a habituation mechanism to regulate the exploration-exploitation trade-off, mirroring how biological attention systems filter redundant stimuli whilst remaining responsive to novel events.
Through a comprehensive ablation study comparing Deep Q-Learning (DQL), Vanilla Q-Learning (VQL), and Multi-Objective Q-Learning (MOL), we uncover a critical insight: habituation significantly enhances DQL performance, improving response efficiency and policy stability, yet causes systematic degradation in MOL due to fundamental incompatibilities between fixed-threshold resets and the extended episodes required for multi-objective optimisation.
This differential effect reveals that bio-inspired mechanisms cannot be applied universally across learning architectures but must be carefully matched to algorithmic characteristics. Real-world deployment on the ARI humanoid robot validates the framework's practical applicability, achieving 95.1% accuracy (95% CI: [92.7%, 96.7%]) across 448 trials with well-calibrated confidence metrics that reliably distinguish correct from incorrect predictions.
Video Demo
Research Context & Motivation
Social robotics is expanding rapidly across assistive care, education, and entertainment, demanding robots with bio-inspired, human-like characteristics. Among these, the ability to direct and regulate attention stands as a fundamental challenge. Real-time attention allocation in multiparty scenarios requires identifying and prioritising salient stimuli in dynamic, ambiguous environments — essential for effective human-robot interaction.
Current approaches suffer from fundamental constraints that limit real-world deployment. Performance degrades beyond 2-3 participants as computational complexity grows exponentially, systems demonstrate poor temporal modelling, and reliance on deterministic handcrafted mappings constrains adaptability to novel scenarios. This gap stems from the underdeveloped translation of biological attention mechanisms to robotics.
Among missing mechanisms, habituation — fundamental to biological learning and attention regulation — is particularly promising yet severely underutilised. Current implementations employ simplistic exponential decay, failing to capture stimulus specificity, spontaneous recovery, and dishabituation responses. A critical question emerges: under what conditions do bio-inspired mechanisms enhance learning, and when might they interfere with algorithmic requirements?

Figure 1: A triadic social HRI between ARI humanoid robot and two study humans, demonstrating real-world deployment of the bio-inspired attention adaptation framework at the Robot House, University of Hertfordshire, UK.
Methodology: Bio-Inspired Attention Framework
Implements stimulus specificity, spontaneous recovery, and dishabituation responses within the RL exploration-exploitation framework. When the agent becomes stuck (exceeding a step threshold), dishabituation temporarily restores full exploration; spontaneous recovery prevents erasing prior learning progress after a reset.
Comprehensive 3 x 2 factorial design: three RL methods (DQL, VQL, MOL) x two exploration modes (standard epsilon decay vs. habituation) x 9 independent runs per configuration, yielding over 55,000 test episodes.
Reward function grounded in empirical human eye-tracking data using the Elicited Attention model. Integrates social features (Gaze Control Scores) with proxemic zones (personal, social, public) for ecologically valid learned behaviours.
Discrete 8-action gaze control (6 people + environment + objects) with real-time inference at 30 Hz on ARI's onboard computer. Processes social cues, gestures, and proximity for human-like attention allocation in multiparty scenarios.
Algorithm 1: Bio-Inspired Habituation Mechanism
Initialise: ε ← 1.0, εprev ← 1.0, τ ← 10
Parameters: decay δ = 0.995, minimum εmin = 0.01
for each episode e = 1, 2, … do
steps ← 0, reset_occurred ← False
while not terminal state do
Select action via ε-greedy policy
Execute action, observe reward and next state
steps ← steps + 1
if steps > τ and not goal_reached then
εprev ← ε; ε ← 1.0 {Dishabituation}
reset_occurred ← True
end if
end while
if goal_reached and reset_occurred then
ε ← εprev {Spontaneous recovery}
else
ε ← max(εmin, ε × δ) {Normal decay}
end if
end for
The mechanism operates through three key biological properties: Habituation corresponds to the standard exponential decay of the exploration rate. Dishabituation occurs when the agent becomes stuck (exceeding τ steps without reaching the goal state), temporarily restoring full exploration. Spontaneous recovery occurs after successful goal achievement following a dishabituation reset, restoring the previous ε value to prevent erasing prior learning progress.
Reward Structure: Elicited Attention Model
The reward function is grounded in empirical human eye-tracking data from a study with 11 participants at the Technical University of Munich, who viewed a 7-minute dyadic conversation video recorded with synchronised HD and Kinect RGB-D cameras. The Elicited Attention (EA) formula integrates social features, proxemics, orientation, and attention memory:
EAs,j(t) = Fs,j + P(d) + O(θ) + EAMs,j
The total reward is simplified to rt(s, a) = Fs,j + P(d), combining social features with proximity. The high discount factor (γ = 0.988) ensures the agent plans over ~83 steps into the future, capturing temporal dynamics of social attention.
Gaze Control Scores (Social Feature Priorities)
| Priority | Social Cue | Gaze Control Score |
|---|---|---|
| 1 | Entering | 100 |
| 2 | Speaking | 100 |
| 3 | Hand motion / Gesture | 65 |
| 4 | Leaving | 55 |
| 5 | Facial expression | 45 |
Proxemic Zone Weights
Six Key Contributions
- Bio-inspired habituation mechanism: Implements stimulus specificity, spontaneous recovery, and dishabituation — addressing the critical gap in bio-inspired attention mechanisms that rely on simplistic exponential decay
- Comprehensive ablation study: 54 independent experiments with rigorous statistical analysis (paired t-tests, one-way ANOVA, Cohen's d) revealing the differential impact of habituation across learning architectures
- Systematic baseline comparisons: Results contextualised against a rule-based controller (94.2% success), standard epsilon-greedy exploration, and random policy baseline (12.5%)
- Empirically-grounded reward structure: Derived from human eye-tracking data using the Elicited Attention model, ensuring ecological validity in learned policies
- Real-time performance: 30 Hz inference on ARI's onboard computer, with training completing in approximately 45 minutes per 10,000-episode run
- Real-world deployment: 95.1% accuracy (95% CI: [92.7%, 96.7%]) across 448 trials with 3 experimenters, with per-class F1-scores of 0.63-0.78 for human-directed attention
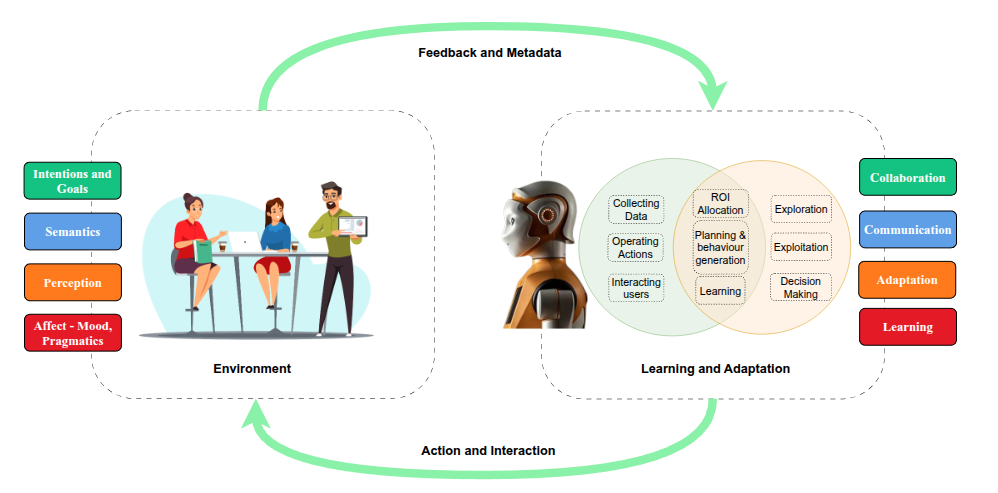
Figure 2: The RLBAM framework architecture demonstrating the integration of habituation mechanisms with multi-objective Q-learning for adaptive robotic attention control.
System Architecture & Training
Three RL Architectures Compared
Neural network function approximator with two hidden layers (128 and 64 units), ReLU activations, and experience replay for decorrelating sequential samples. A target network stabilises training. Naturally suited to the discrete 8-action gaze decision space with value enumeration and interpretable Q-value confidence metrics.
Tabular Q-table with discrete state representation and learning rate α = 0.1. Provides a non-parametric baseline — its tabular structure produces near-uniform softmax distributions regardless of policy quality, yielding low confidence scores (0.22-0.23) but perfect success rates.
Vector Q-table maintaining separate Q-values for six objectives: task success, proximity to target, gaze direction alignment, social appropriateness, movement smoothness, and energy efficiency. Naturally requires longer episodes, creating fundamental incompatibility with the fixed habituation threshold (τ = 10).
State & Action Spaces
Each state s ∈ ℝn encodes person activities, proximity measurements, and count derived from Kinect-based sensing. The environment comprises interactive states (one or more people present) and non-interactive states (no individuals or no active engagement). The action space comprises 8 discrete gaze control options:
Hyperparameters & Training Configuration
Simulation Environment
Training was conducted in NVIDIA IsaacSim, constructing environments featuring humans and a social robot receptionist with scenarios including person entry, interaction activities (hand-waving, speech), and multiparty conversations. Each 10,000-episode training run completes in approximately 45 minutes on a standard workstation, with a memory footprint below 2 GB. Real-time inference operates at 30 Hz on the ARI robot's onboard computer.
Six Evaluation Metrics
Proportion of test episodes where the agent successfully directs gaze to the appropriate target.
Response efficiency — directly relevant to real-time HRI where delays disrupt interaction flow.
Probability mass assigned to the selected action, reflecting decisiveness of the learned policy.
Gap between best and second-best Q-values — confidence metric independent of the softmax function.
Composite: success (40%) + efficiency (30%) + confidence (20%) + normalised reward (10%).
How often habituation triggers dishabituation — reveals compatibility between mechanism and algorithm.
Results & Experimental Validation
Performance Highlights:
- DQL+HAB achieves 100% success rate across 9,180 test episodes with the highest transfer score (0.963 +/- 0.010)
- 95.1% real-world accuracy (95% CI: [92.7%, 96.7%]) across 448 trials with 3 experimenters on the ARI humanoid robot
- Critical finding: Habituation enhances DQL but causes systematic degradation in MOL (97.8% success, 164x more resets) — bio-inspired mechanisms are architecture-dependent
- Well-calibrated confidence: Spearman correlation between confidence and correctness of 0.42 (p < 0.001) enables principled online error detection
Ablation Study: Simulation Results (54 Experiments)
The experimental design follows a 3 x 2 factorial structure: three RL methods (DQL, VQL, MOL), two exploration modes (standard epsilon decay EPS vs. habituation HAB), and 9 independent runs per configuration. Each run comprises 10,000 training episodes followed by evaluation on 51 test states with 20 iterations each, yielding over 55,000 test episodes across all conditions.
Table II: Complete Ablation Results (mean +/- SD across 9 runs)
| Method | Mode | Success Rate | Avg Steps | Confidence | Q-Margin | Transfer Score |
|---|---|---|---|---|---|---|
| DQL | HAB | 1.000 +/- 0.000 | 2.08 +/- 0.56 | 0.878 +/- 0.043 | 5.00 +/- 1.70 | 0.963 +/- 0.010 |
| DQL | EPS | 1.000 +/- 0.000 | 2.31 +/- 0.73 | 0.848 +/- 0.096 | 4.89 +/- 2.23 | 0.956 +/- 0.021 |
| VQL | EPS | 1.000 +/- 0.000 | 3.70 +/- 0.23 | 0.227 +/- 0.056 | 0.29 +/- 0.65 | 0.748 +/- 0.018 |
| VQL | HAB | 1.000 +/- 0.000 | 3.72 +/- 0.10 | 0.224 +/- 0.025 | 0.25 +/- 0.31 | 0.747 +/- 0.008 |
| MOL | EPS | 0.999 +/- 0.001 | 7.84 +/- 1.52 | 0.200 +/- 0.000 | 0.001 +/- 0.001 | 0.717 +/- 0.005 |
| MOL | HAB | 0.978 +/- 0.013 | 16.14 +/- 5.02 | 0.200 +/- 0.000 | 0.000 +/- 0.000 | 0.684 +/- 0.020 |
Key Findings
- DQL dominance: Both DQL configurations achieved perfect 100% success rates. DQL-HAB shows the best overall transfer score (0.963), highest confidence (0.878), and lowest variance in average steps. DQL assigns 85-88% probability to its chosen action, producing confident, purposeful gaze shifts within 70-80 ms (2 steps x 33 ms) — well within the 200-300 ms window of natural human gaze shifts
- VQL robustness: Also achieved 100% success rate; habituation has essentially zero effect on VQL performance (negligible Cohen's d values < 0.2), consistent with its tabular structure that doesn't benefit from adaptive exploration bursts
- MOL degradation: Habituation causes catastrophic interference in MOL — success drops from 99.9% to 97.8% (paired t-test: t = 4.89, p = 0.001, Cohen's d = 2.28), with average steps more than doubling from 7.84 to 16.14. At 30 Hz, MOL-HAB's 16.14 steps translate to >500 ms — perceptibly unnatural in social interaction
- Root cause: MOL averages 7,368 habituation resets per run (164x more than DQL's 44.9), because the fixed step threshold (τ = 10) misinterprets the legitimately longer episodes required for multi-objective optimisation as stuck states. In 73.7% of MOL-HAB training episodes, habituation is triggered — preventing stable exploitation
Habituation Reset Statistics
Reset frequency reveals fundamental compatibility between the habituation mechanism and the learning architecture:
| Method | Resets / Run | Reset Ratio (vs DQL) | Interpretation |
|---|---|---|---|
| DQL | 44.9 +/- 9.8 | 1.0x | Efficient |
| VQL | 93.3 +/- 7.3 | 2.1x | Acceptable |
| MOL | 7,368.2 +/- 28.6 | 164x | Pathological |
Statistical Analysis (HAB vs. EPS within each method)
| Method | Metric | t-statistic | p-value | Cohen's d | Effect Size |
|---|---|---|---|---|---|
| DQL | Avg Steps | 0.59 | 0.573 | 0.35 | Small |
| DQL | Confidence | -0.74 | 0.482 | 0.40 | Small |
| DQL | Transfer Score | -0.62 | 0.551 | 0.37 | Small |
| VQL | Avg Steps | -0.21 | 0.836 | 0.10 | Negligible |
| VQL | Confidence | 0.15 | 0.882 | 0.07 | Negligible |
| VQL | Transfer Score | 0.21 | 0.840 | 0.09 | Negligible |
| MOL | Success Rate | 4.89 | 0.001** | 2.28 | Large |
| MOL | Avg Steps | -5.40 | <0.001** | 2.24 | Large |
| MOL | Transfer Score | 3.56 | 0.007** | 1.67 | Large |
Cross-Method ANOVA (DQL vs. VQL vs. MOL)
All metrics show highly significant method effects, confirming that architecture choice matters enormously for attention control performance:
| Metric | EPS F-stat | EPS p-value | HAB F-stat | HAB p-value |
|---|---|---|---|---|
| Success Rate | 4.00 | 0.032* | 25.07 | <0.001*** |
| Avg Steps | 77.23 | <0.001*** | 62.61 | <0.001*** |
| Confidence | 292.33 | <0.001*** | 1580.88 | <0.001*** |
| Q-Margin | 34.12 | <0.001*** | 98.47 | <0.001*** |
| Transfer Score | 189.56 | <0.001*** | 277.34 | <0.001*** |
Transfer Score Rankings (with 95% Confidence Intervals)
Non-overlapping confidence intervals between DQL configurations and all other methods provide statistical confirmation (>95% confidence) that DQL+HAB will outperform any non-DQL configuration in future deployments.
Real-World Deployment (448 Trials)
The trained DQL-HAB model was deployed on the ARI humanoid robot at the Robot House, University of Hertfordshire, transitioning from the controlled precision of simulation to the messy complexity of physical embodiment. The experiment involved 3 experimenters, all affiliated with the university, engaged in structured social interactions through 448 distinct trials across four state categories.
Accuracy by Scenario Category
| Category | Trials | Accuracy | 95% CI |
|---|---|---|---|
| Two experimenters | 157 (35%) | 98.1% | [94.5%, 99.3%] |
| Three experimenters | 112 (25%) | 96.4% | [91.2%, 98.6%] |
| Single experimenter | 112 (25%) | 93.8% | [87.7%, 96.9%] |
| Low saliency | 67 (15%) | 88.1% | [78.2%, 93.8%] |
| Overall | 448 | 95.1% | [92.7%, 96.7%] |
Per-Class Performance Metrics
| Action Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Gaze_At_Experimenter_2 | 0.667 | 0.952 | 0.784 | 105 |
| Gaze_At_Experimenter_1 | 0.724 | 0.728 | 0.726 | 169 |
| Gaze_At_Experimenter_3 | 0.609 | 0.654 | 0.631 | 107 |
| Gaze_At_Environment | 0.400 | 0.030 | 0.056 | 67 |
| Gaze_At_Object | 0.000 | 0.000 | 0.000 | 0 |
| Macro Average | 0.600 | 0.591 | 0.549 | 448 |
Confidence Calibration & Error Detection
The strong correlation between confidence and correctness suggests well-calibrated uncertainty estimates that could enable adaptive behaviours: the robot could request clarification when confidence drops below 0.60, or flag predictions with Q-margins below 1.5 for human oversight.
Observed Real-World Behaviours
The experimental protocol progressed through increasingly complex scenarios. Across this progression, RLBAM demonstrated several key capabilities:
- Immediate gaze redirection: Upon person entry, the robot redirected gaze within an average of 2.3 steps, consistent with simulation performance
- Appropriate disengagement: When humans adopted passive stances (attending to objects rather than the robot), the agent appropriately shifted attention
- Seamless departure recovery: Following person departure, the agent redirected to the next most salient stimulus rather than fixating on empty space
- Dynamic priority adjustment: In multiparty scenarios, smooth tracking of gesturing persons and rapid attention switching between simultaneously present individuals confirmed sim-to-real generalisation without catch-up saccades or fixation loss
Sim-to-Real Gap Decomposition
The 4.9 percentage point performance gap (100% simulation to 95.1% real-world) can be decomposed into identifiable sources:
Critically, performance does not increase with scenario complexity — three-experimenter states (96.4%) match or exceed single-experimenter (93.8%), indicating robust policy generalisation rather than memorisation.

Figure 3: Training dynamics and behavioural analysis showing habituation-guided exploration, reward progression, and convergence patterns across 10,000 episodes per run (54 independent experiments).
Impact & Future Directions
This work provides the first systematic evidence that bio-inspired habituation mechanisms are architecture-dependent rather than universally beneficial — a finding with broad implications for the intersection of cognitive science and reinforcement learning. By rigorously demonstrating that the same biological principle can enhance, leave unchanged, or degrade performance depending on the underlying learning architecture, this research challenges the common assumption that bio-inspired mechanisms are generically advantageous.
Broader Implications
- Social Robotics: Delivers a deployable, real-time (30 Hz) gaze control system achieving 95.1% accuracy in unstructured multiparty environments, advancing natural human-robot interaction in care, education, and entertainment domains
- Cognitive Science: Provides computational validation of biological habituation phenomena (stimulus specificity, spontaneous recovery, dishabituation) while revealing that not all learning systems benefit equally — mirroring observations in biological neural circuits
- Reinforcement Learning: Offers a principled methodology for integrating bio-inspired exploration mechanisms with RL, including diagnostic tools (reset frequency analysis, step-count distributions) to predict compatibility before deployment
- Sim-to-Real Transfer: Demonstrates that policies trained with bio-inspired exploration exhibit robust transfer (only 4.9% accuracy drop), with a decomposition framework attributing the gap to sensor noise (2.5%), distribution shift (1.5%), and policy limitations (0.9%)
Comparison with Prior Work
RLBAM advances over the current landscape of learning-based gaze systems:
- vs. RASA (76.9% dyadic accuracy): RLBAM achieves 95.1% in more challenging multiparty scenarios, demonstrating the advantage of RL over rule-assisted approaches
- vs. Multi-party systems (97% effectiveness): These systems mask critical limitations in scalability, temporal modelling, and adaptability; RLBAM achieves comparable accuracy with genuine online adaptation capability
- vs. Rule-Based Controller (94.2% success): RLBAM's learned policy (95.1%) exceeds the deterministic baseline whilst handling ambiguous scenarios requiring temporal reasoning and adaptation to novel situations
- vs. Policy gradient / Actor-critic methods: These require large amounts of training data with limited transferability across social contexts; RLBAM trains in ~45 minutes and transfers robustly from simulation
- vs. Transformer-based attention prediction: Whilst achieving high accuracy on fixation patterns, these supervised approaches lack the adaptive online learning capability essential for personalised HRI
Limitations
- Scalability: The current system supports up to 6 simultaneous persons, constrained by Kinect sensor detection capacity. DQL's neural network handles state space growth more gracefully than tabular methods, but scenarios exceeding 6 participants would require architectural extensions such as hierarchical attention or graph-based state representations
- Social context: The reward function encodes Western-centric gaze norms where direct eye contact and proximity signal engagement. However, gaze norms vary significantly across cultures — in some East Asian cultures, sustained direct gaze may be perceived as confrontational; in certain Middle Eastern cultures, gender-differentiated gaze patterns are socially expected. Adapting to diverse cultural contexts would require culture-specific reward function parameterisation
- Generalisation beyond triadic interaction: Whilst real-world validation involved up to 3 experimenters, the architecture accommodates up to 6 persons. Validation with larger groups, unstructured environments, and naturalistic (non-scripted) interactions remains essential future work
- Fixed habituation threshold: The fixed τ = 10 steps works well for single-objective learning but becomes pathological for multi-objective methods. Only changing the threshold to 30-50 steps or making it adaptive could potentially salvage the approach for MOL
Future Research Directions
- Adaptive threshold selection: Adjusting τ based on task complexity, with thresholds of 30-50 steps being more appropriate for multi-objective scenarios
- Continual policy adaptation: Through lifelong learning or meta-reinforcement learning, enabling the system to personalise attention strategies for individual users over extended deployments
- Semantic scene parsing integration: Adding affective state recognition to enrich the state representation beyond activity and proximity features
- Cross-cultural reward functions: Potentially learned through observation of culturally situated interactions
- Large-scale longitudinal studies: Open-world environments to assess both generalisability and social acceptability of the robot's gaze behaviours across diverse demographic groups
Paper Access & Resources
IEEE Transactions on Cognitive and Developmental Systems (TCDS)