About the Paper
Presented at IEEE-RAS Humanoids 2024, this work demonstrates how the ARI humanoid robot acquires robust, human-like social gaze behaviour using deep reinforcement learning (RL), domain randomisation, and zero-shot sim-to-real transfer. We trained an attention model using Proximal Policy Optimisation (PPO) in simulation — then directly deployed it on ARI for real-world human-robot interaction (HRI) scenarios, achieving natural saliency-driven gaze and reliable adaptation to new people and activities. The approach tackles a core challenge in social robotics: robust transfer of RL policies from simulation to reality, enabling real-time, context-sensitive attention in complex, dynamic environments.
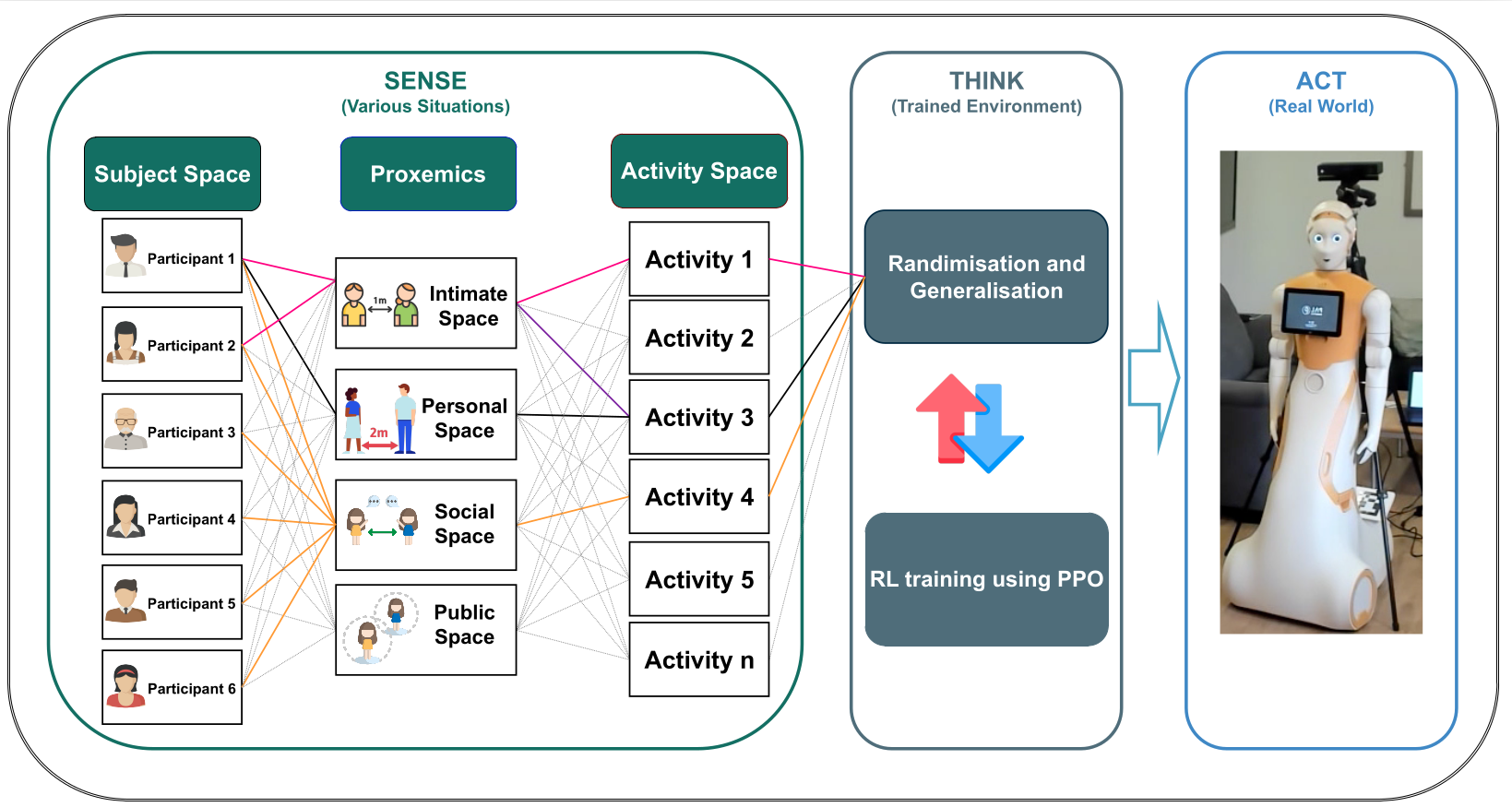
Figure 1: Workflow and example of the ARI robot dynamically allocating gaze between participants based on activity, proximity, and social cues, driven by RL policy trained in simulation.
ARI Robot Gaze Learning Explained
This video explains how the ARI humanoid robot learns human-like gaze behaviour through deep reinforcement learning. Watch how we use Proximal Policy Optimisation (PPO), domain randomisation, and zero-shot sim-to-real transfer to train robust social attention models that generalise from simulation to real-world human-robot interaction without additional training.
Live Demo: ARI Robot in Real-World HRI
Watch the ARI humanoid robot in action, demonstrating learned gaze behaviour in real-world human-robot interaction scenarios. The robot dynamically allocates attention between multiple participants based on social cues, proximity, and activities — all driven by the reinforcement learning policy trained in simulation and transferred without additional training.
Why Social Gaze Matters in HRI
Gaze behaviour is a core channel for nonverbal communication and social presence in HRI. For a robot to be accepted as a social peer, it must identify salient participants and respond to dynamic social cues — just as humans do. Traditional hand-crafted gaze rules fail in unstructured or multi-party environments. Our RL-based model enables ARI to learn these nuanced behaviours directly from simulated experience, generalising to new people, positions, and activities in the real world.
Methodology
- Randomisation & Generalisation: We use domain randomisation to generate diverse training states: up to six people, random combinations of activities (speaking, entering, gestures, etc.), and proximity (intimate, social, public). This builds a robust policy that handles real-world variability.
- Reward Function: Our reward is based on an elicited attention (EA) score, adapted from human social attention research. The RL agent receives maximal reward for gazing at the participant performing the highest-priority, socially salient activity in closest proximity.
- Training & Architecture: PPO is trained in Gym and RayRL environments. The agent observes participant activities and distances; actions are gaze directions (at environment, objects, or participants 1-6). Hyperparameters are carefully tuned (entropy coefficient, gamma, learning rate) for fast convergence and robust exploration.
- Sim-to-Real Pipeline: After convergence, the RL policy is integrated with ARI's ROS-based control system. Kinect V2 provides participant tracking; decisions are sent via ZeroMQ to the robot for real-time gaze control.
- Zero-Shot Transfer: No additional training or adaptation is required after simulation — the agent generalises directly to the real world using robust, diversified policy learning.
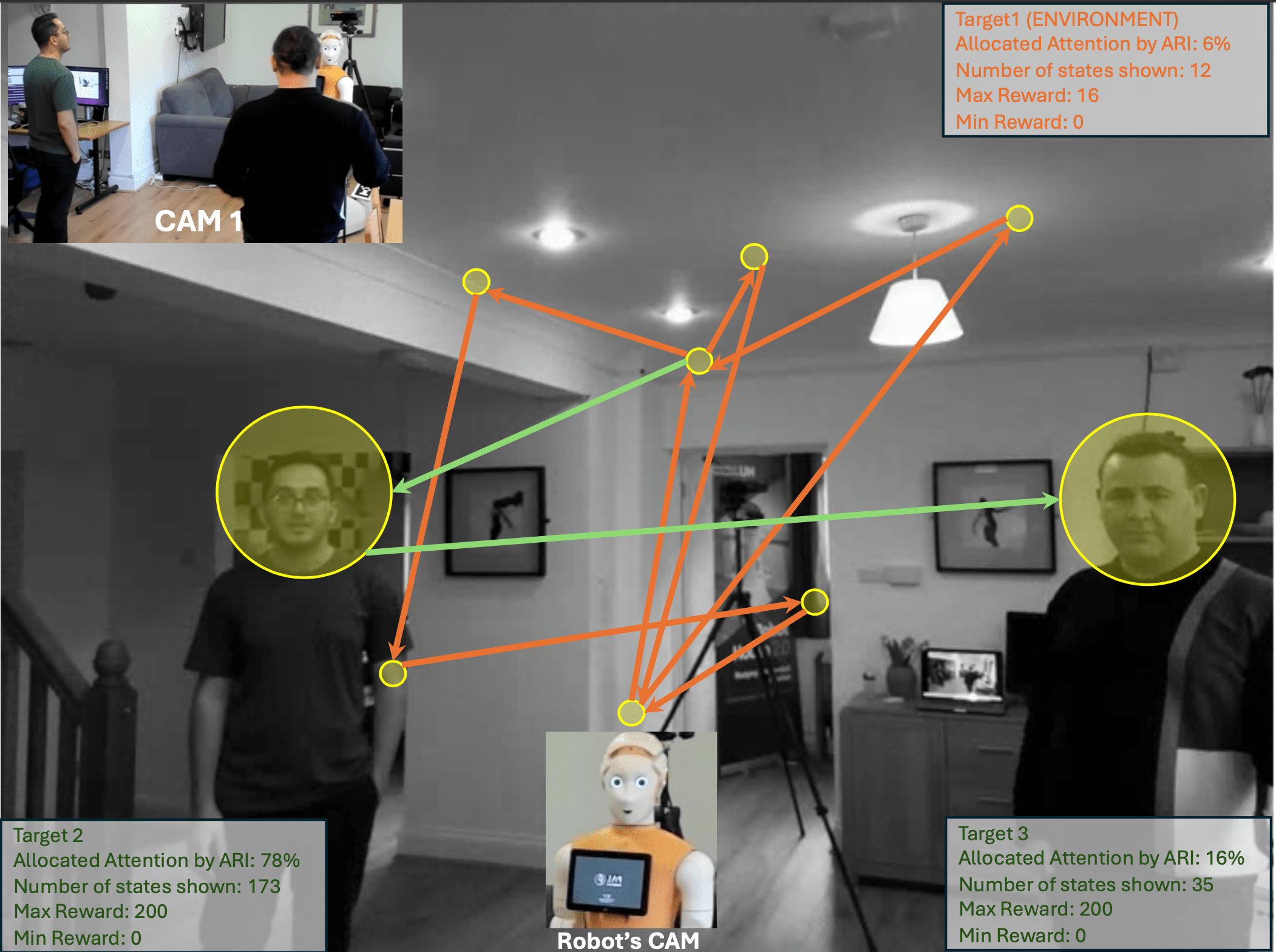
Figure 2: Example from real-world trials. ARI dynamically allocates attention between environment, participant 1, and participant 2 in live triadic HRI, mirroring human-like saliency and prioritisation. RL agent selects gaze targets based on real-time EA scoring.
Results & Evaluation
- Attention Allocation: In real HRI, ARI correctly prioritised and gazed at the most socially salient participant (e.g., entering, speaking, hand gestures) in 94% of trials, and mimicked human-like low-level scanning when no one was present.
- Robustness & Generalisation: The model generalised to previously unseen combinations of activities, proximity, and participants, overcoming the sim-to-real gap without post-deployment retraining.
- Sample Data: During one scenario, ARI looked at participant 1 (high-priority activities) in 78.6% of frames, at participant 2 (lower priority) 15.9%, and at the environment when no participants were present — fully consistent with the designed EA reward and human reference data.
- Quantitative Plots: Mean episode reward steadily increased and stabilised after ~60k simulation episodes, showing effective and stable learning.
- Proof-of-Concept: The robot performed error-free saliency target selection in multi-person HRI, as validated by comparison with ideal action tables and ground-truth annotations.
Challenges & Future Directions
- Sensor noise and real-world perception limits remain a bottleneck — domain randomisation helps but cannot eliminate all artefacts.
- Hyperparameter tuning (entropy, learning rate, PPO clip, gamma) is essential for robust and fast convergence; future work will integrate model-based RL and sensor fusion for even greater fidelity and adaptability.
- Extending this approach to multi-robot and crowded HRI, as well as integrating memory and dialogue, is a promising next step.
Open Science, Paper, and Code
Published at IEEE-RAS Humanoids 2024.